
This is the second installment of our “FHIR Starter” series, which we are writing to help teams filter out the noise and excitement of the burgeoning FHIR community so they can focus on the signal–how to be successful with real-world FHIR implementations. If you missed our first installment, check that out here.
In this installment, we take a quick tour of some core FHIR principles, then dive into a modern-day example of the ubiquitous “hello world” exercise with a FHIR server implementation.
From Hand Wave to Hello World
As FHIR momentum grows, an increasingly common mandate from senior management teams will become something like “Get that FHIR thing done.” We affectionately refer to this as the “hand wave mandate.” Senior leaders don’t need to know all the details. Figuring out the details is why they pay their teams the big money (well, some money anyway).
As we shared in FHIR Starter #1, FHIR is great, but “getting it done” requires more than just hand waves. On the other hand, getting started is much easier than it could be; “easy-ish” is an apt characterization.
Core FHIR Ideas
Before jumping into an implementation, let’s cover a few FHIR core principles. Many senior leaders don’t care about the details behind these ideas; they have just heard that FHIR is gaining momentum and that it is “modern” or “lightweight” (unlike the legacy technology they keep hearing their teams complain about). However, these principles provide a good vocabulary for understanding by all stakeholders of the foundation of FHIR architecture. I am summarizing them here, but they are covered in the depth they deserve in the core FHIR specifications–starting here.
- Modern Web API Standards – FHIR APIs are RESTful, so they behave like most modern-day APIs. This promises to vastly improve performance and maintainability compared to the old ways of moving healthcare data, and it means an easier learning curve for most developers.
- HTTP(S) – Nothing new here, but FHIR uses standard transactions that are part of HTTP standards (like GET, POST, PUT, PATCH), and FHIR takes advantage of conventions like HTTP headers, standard error codes, and more.
- Granular Resources – FHIR defines resources, like “Patient,” that are bite-sized chunks of data. FHIR Resources are the building blocks of FHIR interactions; they can be exchanged either individually or grouped into bundles of resources. Compared to legacy healthcare interoperability specifications, this is a game-changer, because it means that just the information needed can be exchanged by using FHIR.
- Extensibility – The base FHIR specification is designed to be extended for specific use cases. This has pros and cons, of course, but it provides more flexibility than previous healthcare interoperability standards.
- Flexible Payloads – FHIR transactions use RESTful API standards, but payloads can also include XML, such as legacy CDA documents, to make interoperability with legacy systems less painful.
FHIR is designed to embrace the way the internet works.
FHIR Implementations: Deceptively Easy-ish
I mentioned in FHIR Starter 1 that despite all the improvements FHIR brings, realizing that potential in FHIR implementations is not “easy” because healthcare is pretty complicated, and few things in healthcare are easy.
This is true, but getting to “hello world” is not difficult.
Getting a FHIR server created, deployed, and running is easy. Teams don’t have to become FHIR experts, they don’t have to memorize the FHIR specifications, and they don’t have to become experts in the latest trendy programming language or application framework.
In fact, they don’t have to do any programming at all. A functional FHIR server can be spun up using one of several off-the-shelf, freely available, FHIR implementations. Probably the most widely used example is the open-source HAPI FHIR server sponsored by the Smile Digital team.
A team could clone the HAPI FHIR JPA Server repository (here), or a team could spin up an instance of the HAPI FHIR Server hosted by Microsoft’s Azure service, one of several options offered by AWS or others.
Hello World
Getting to “hello world” with FHIR doesn’t even require spinning up your own FHIR server.
You can simply point your favorite browser to https://hapi.fhir.org/ to immediately access the public HAPI FHIR Test Server. This URL defaults to an operating implementation of FHIR release 4 (“FHIR R4”), which is the version of FHIR currently used by most FHIR implementers in production.
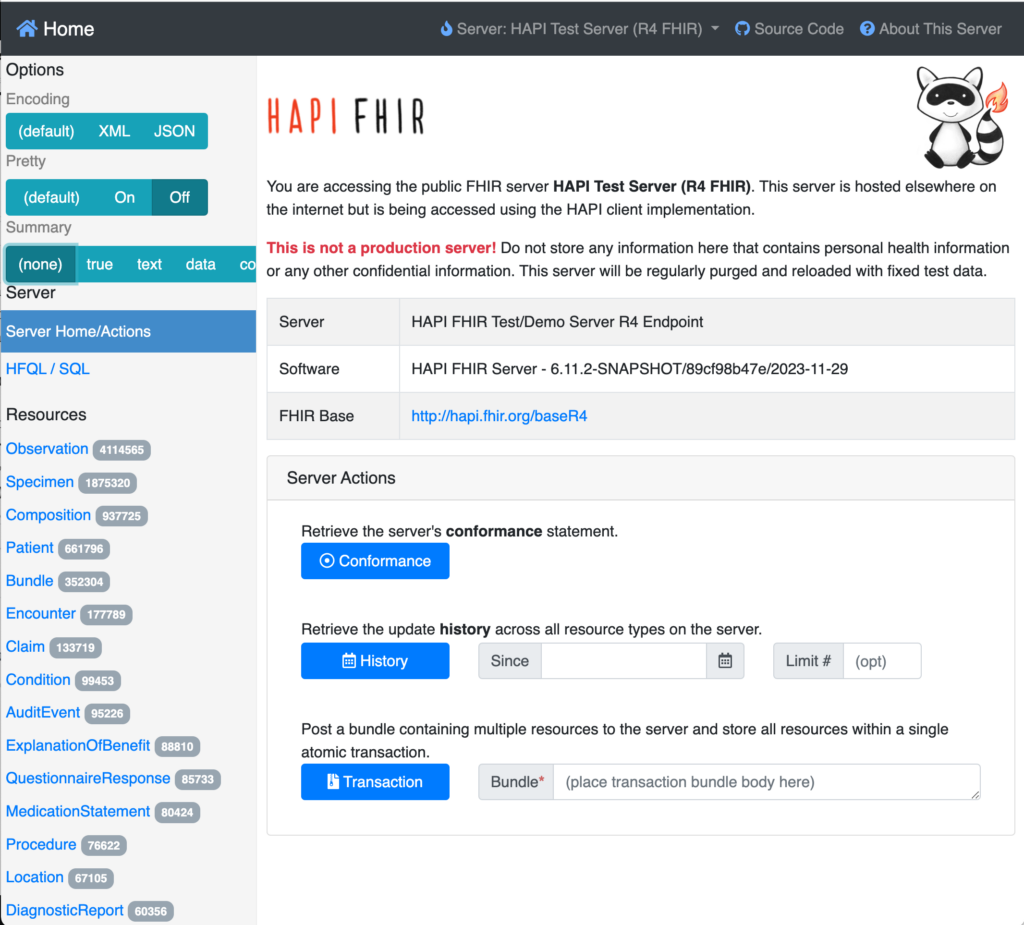
As you can see from the list of Resources on the left, there is a lot of (synthetic) healthcare data on this server, and this server appears to support many use cases. For example, in addition to the obvious clinical resources like Observation, Encounter, Procedure, and Diagnostic Report, we also see ExplanationOfBenefit and Claim.
This speaks to the power of FHIR to cover many healthcare interoperability scenarios from a single implementation.
FHIR Conformance Statement – “What I Support”
By clicking on that “Conformance” button, we see a response starting with this:
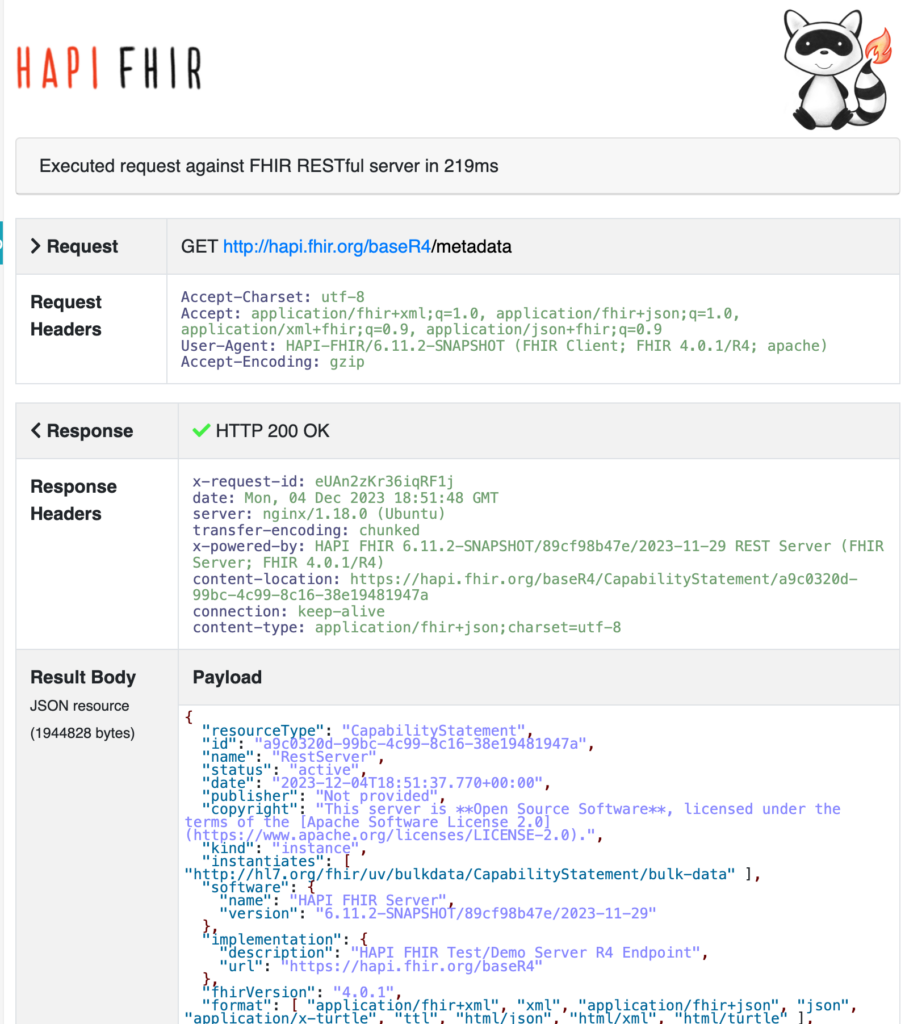
The FHIR Conformance Statement is intended to accurately communicate the detailed FHIR capabilities a given FHIR server implementation supports. This example is formatted in JSON, and it can be easily made human-friendly, but the main idea is that FHIR servers can retrieve and interpret FHIR Conformance Statements to set accurate expectations about the interactions supported by each. The implications of that are exciting.
This example is very large (not surprising, given all the supported resources shown in that Resources list on the left). Let’s hit some highlights:
“resourceType”: “CapabilityStatement” – Everything in FHIR is a resource, including the Capability Statement. All FHIR payloads name their included resource(s) like this.
“kind”: “instance” – This means that the CapabilityStatement resource content represents the present capabilities of this specific system instance. I mention this because there are also Capability Statements created for FHIR Implementation Guides. In that case, the Capability Statement represents what should be implemented to be conformant to that IG.
“fhirVersion”: “4.0.1” – The precise version of FHIR this server supports. Each major FHIR release has specific versions. This FHIR R4 FHIR server supports the specific FHIR version 4.0.1 (which is the FHIR R4 version the is currently the most widely supported in production).
- Note that some of this information is also shown in the HTTP headers near the top of this response. Like most modern-day web APIs, FHIR uses HTTP headers to convey specific information the recipient can process before processing the larger payload. This Accept header listing the flavors of FHIR-specific JSON and XML is a great example
- Accept: application/fhir+xml;q=1.0, application/fhir+json;q=1.0, application/xml+fhir;q=0.9, application/json+fhir;q=0.9
Scrolling down, we see many iterations of content like this:

This section begins describing this server’s support of the Patient resource, starting with showing the location of the canonical HL7 resource profile definition, followed by the list of additional Patient profiles supported. Below that, we see the list of interactions supported for Patient by this FHIR server.
Continuing our scroll down this Patient section …

… we see the last portion of the long list of ways the Patient resource can be included in search results, followed by most of the list of Patient attributes supported by this FHIR server.
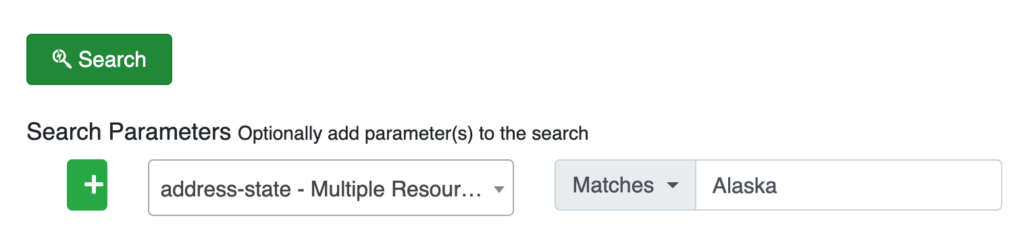
Finally, let’s take a quick look at an example Patient resource returned by this FHIR Server. First I search for patients in Alaska:
From that set of results, I select Read for one of the patients:
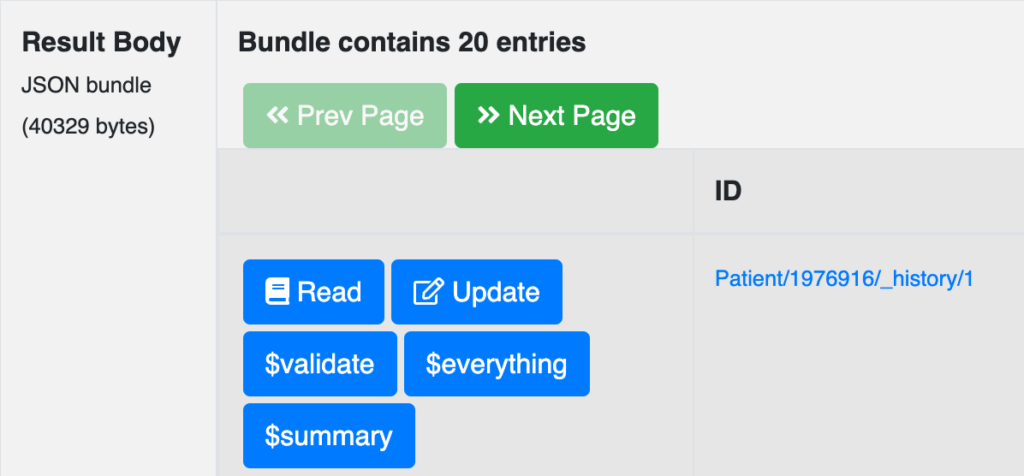
Initial Patient view:
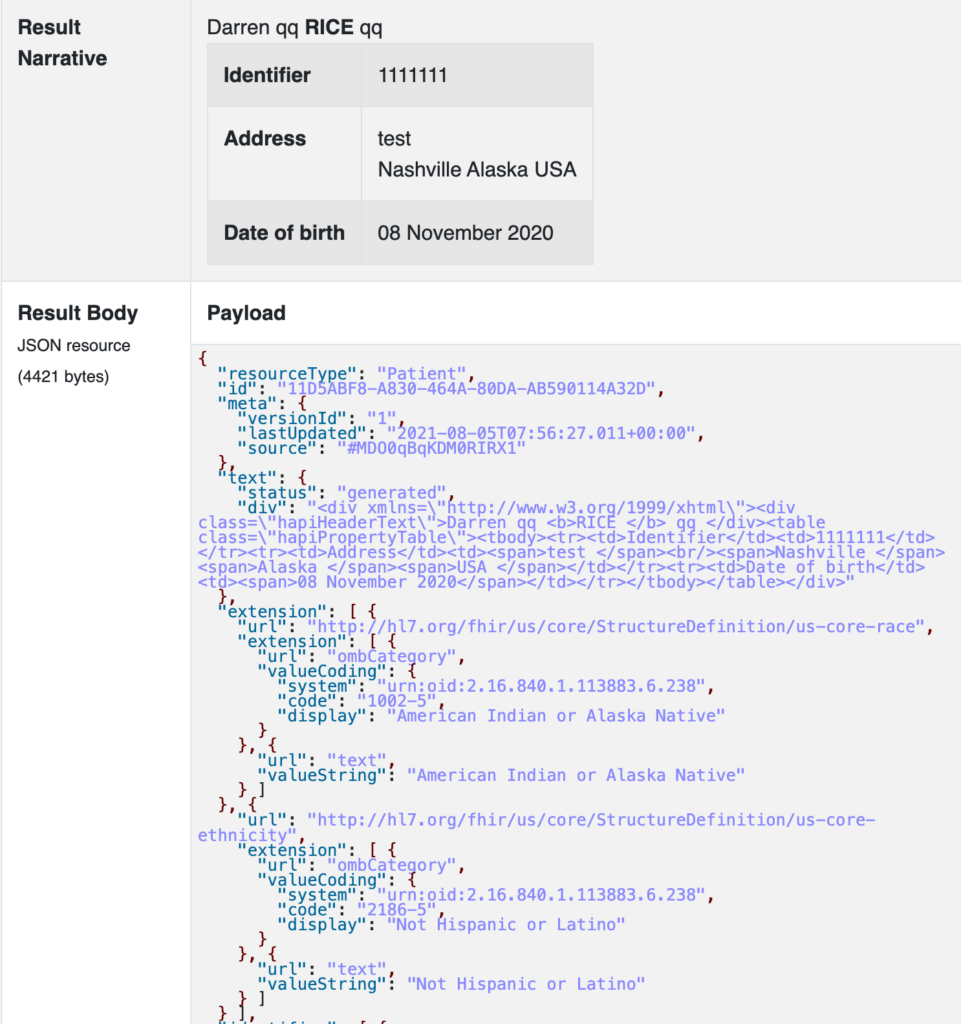
This starts with a nicely formatted “Narrative” showing the patient’s name, identifier, and address, followed by the machine-readable view we are used to seeing.
Note that I could have clicked that “$everything” button (above) to see the entire patient history of care encounters, vaccinations, prescriptions, lab work, etc. (and you can do that yourself by visiting this same FHIR server instance here), but I am betting that you have seen enough for now.
Our Paradox of “Easy”
We have seen a lot of information in this FHIR Starter installment, and it may not be that easy to quickly digest.
On the other hand, that required zero implementation effort. This speaks volumes about the talent and dedication of many talented people in the FHIR community.
Fully functional FHIR server implementations are readily available. No “implementation” effort is required.
This is incredibly helpful and useful–a remarkable catalyst for realizing the potential of FHIR.
Advancing Beyond “Hello World”
So far, we have focused on baseline FHIR specifications–the “foundation” of FHIR. We have noticed how comprehensive those base FHIR specifications are, but when we start to consider specific use cases, we need to look at FHIR Implementation Guides (IGs) which build on base FHIR specifications.
This adds a layer of complexity, and that means more implementation effort. Our next installment will dig into the implications of FHIR IGs.
One thought on “FHIR Starter #2”